JPA 3강 - 필드와 컬럼 매핑
데이터베이스 스키마 자동 생성하기
- DDL(Data Definition Language: CREATE, ALTER, DROP, RENAME 등등)을 애플리케이션 실행 시점에 자동 생성
- 테이블 중심 -> 객체중심
- 데이터베이스 방언을 활용해서 데이터베이스에 맞는 적절한 DDL 생성
- 이렇게 생성된 DDL은 개발 장비에서만 사용
- 생성된 DDL은 운영서버에서는 사용하지 않거나, 적절히 다듬은 후 사용
- hibernate.hbm2ddl.auto(persistence.xml 옵션)
- create : 기존 테이블 삭제 후 다시 생성(DROP + CREATE)
- create-drop : create와 같으나 종료시점에 테이블 DROP(테스트 코드에서 사용하기 좋다.) 즉 DROP + CREATE + DROP이다.
- update : 변경분만 반영(운영DB에서는 사용하면 안됨)
- valiadate : 엔티티와 테이블이 정상 매핑되었는지만 확인(엔티티와 테이블이 똑같은지)
- none : 사용하지 않음
- 운영 장비에는 절대 create, create-drop, update 사용하면 안된다.
- 개발 초기 단계는 create 또는 update
- 테스트 서버는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
실습
- 스키마 자동 생성하기 설정
- 스키마 자동생성하기 실행, 옵션별 확인
persistence.xml 파일을 보자.
- <?xml version="1.0" encoding="UTF-8"?>
- <persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence" version="2.2">
- <persistence-unit name="hello">
- <properties>
- <!-- 필수 속성 -->
- <property name="javax.persistence.jdbc.driver" value="org.h2.Driver"/>
- <property name="javax.persistence.jdbc.user" value="sa"/>
- <property name="javax.persistence.jdbc.password" value="1234"/>
- <property name="javax.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/./test"/>
- <property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect" />
- <!-- 옵션 -->
- <property name="hibernate.show_sql" value="true" />
- <property name="hibernate.format_sql" value="true" />
- <property name="hibernate.use_sql_comments" value="true" />
- <!--<property name="hibernate.hbm2ddl.auto" value="create" />-->
- </properties>
- </persistence-unit>
- </persistence>
JPA 2강에서 실습시 라인 17이 주석처리 되어있었다. 주석을 푼다. create 옵션은 DROP + CREATE 이다. 저장 후 Main 클래스를 실행해보자.
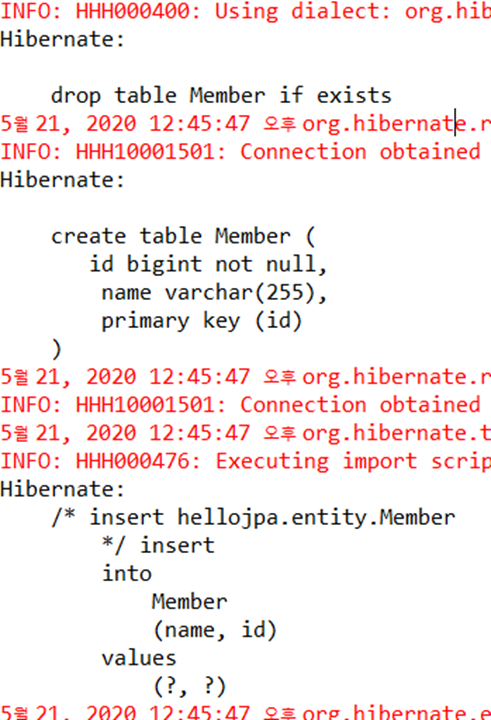
위 결과를 보면 먼저 기존에 있던 MEMBER 테이블을 삭제하고 다시 MEMBER 테이블을 생성한 뒤 데이터를 추가하는 것을 확인할 수 있다. 앞으로는 create로 설정하고 실습하도록 한다. create로 하면 테이블 PK 충돌이 안난다.
매핑 어노테이션(DB와 객체 매핑시 어노테이션)
- @Column
- @Temporal
- @Enumerated
- @Lob
- @Transient
위 어노테이션들은 철저하게 DB에 어떤 식으로 매핑이 될지에 대한 매핑정보이다. 즉, 자바코드에 영향을 주는게 아니라 매핑정보과 관련된 정보라고 보면 된다.
- @Entity
- public class Member {
- @Id
- private Long id;
- @Column (name = "USERNAME")
- private String name;
- private int age;
- @Temporal(TemporalType.TIMESTAMP)
- private Date regDate;
- @Enumerated(EnumType.STRING)
- private MemberType memberType;
- ...
라인 8 private String name은 필드이름이 "name"이라고 되어 있고 바로 위에 라인 7 @Column (name = "USERNAME") 어노테이션이 붙어있다. 이 것은 Member 클래스 name 필드가 데이터베이스에서 USERNAME 컬럼과 매핑이 된다고 보면 된다. 라인 12 @Temporal(TemporalType.TIMESTAMP)은 시간관련 어노테이션이다. 라인 15 @Enumerated(EnumType.STRING)은 자바의 Enum 타입관련 어노테이션이다. @Enumerated 어노테이션 괄호 안에는 꼭 EnumType.STRING을 넣어줘야 한다. 만약 EnumType.ORDINAL(Enum 클래스 필드를 index로 가져옴, 예) 0, 1, 2...)이라고 넣으면 Enum 클래스 필드 중간에 새로운 필드 삽입 시 index가 꼬일 수 있다. 그래서 EnumType.STRING으로 설정해야 한다.
@Column 어노테이션 실습
Main 클래스를 아래와 같이 수정하고 실행해보자.
- @Column(name = "USERNAME")
- private String name;
라인 1에 @Column 어노테이션을 추가시켰다.

결과를 보면 MEMBER 테이블에 USERNAME 컬럼이 추가된 것을 볼 수 있다.
@Enumerated 실습
아래와 같이 hellojpa.entity 패키지 하위에 MemberType Enum 클래스를 만들자.
MemberType Enum 클래스안에 아래와 같이 작성하자.
- package hellojpa.entity;
- public enum MemberType {
- USER, ADMIN
- }
Member 클래스를 아래와 같이 작성하자
- @Enumerated(EnumType.ORDINAL)
- private MemberType memberType;
- public MemberType getMemberType() {
- return memberType;
- }
- public void setMemberType(MemberType memberType) {
- this.memberType = memberType;
- }
- }
라인 1, 2 @Enumerated 어노테이션과 memberType 필드를 추가하고 라인 4 ~ 9 getter, setter 메서드를 추가했다.
main 클래스를 아래와 같이 작성하자.
- try {
- //member 객체를 저장해보자.
- Member member = new Member();
- member.setId(100L);
- member.setName("안녕하세요");
- member.setMemberType(MemberType.ADMIN);
라인 7을 추가했다.
Main 클래스를 실행하고 H2 콘솔을 실행하여 MEMBER 테이블을 조회해보자.
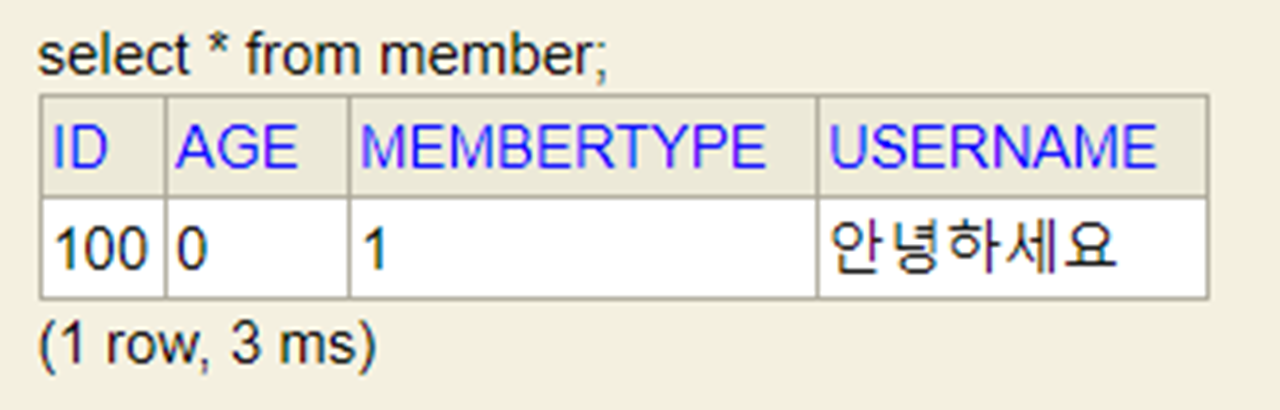
위와 같이 MEMBERTYPE 컬럼이 1로 들어간 것을 볼 수 있다. 만약 이런 식으로 운영에서 쓰면 안된다. MemberType Enum 클래스 중간에 필드를 추가하면 순서가 다 꼬여 버린다. 그래서 아래와 같이 Member 클래스에서 @Enumerated 어노테이션 괄호안에 설정은 라인 1과 같이 EnumType.STRING으로 설정해야 한다. 설정을 안하면 Default가 EnumType.ORDINAL이기 때문에 EnumType.STRING이라고 꼭 명시를 해줘야 한다.
- @Enumerated(EnumType.STRING)
- private MemberType memberType;
EnumType.STRING으로 설정하고 다시 실행해보자.

이번에는 MEMBERTYPE 값이 ADMIN으로 들어가 있다.
@Column
- 가장 많이 사용됨
- name : 필드와 매핑할 테이블의 컬럼 이름
- insertable, updatable : 읽기전용,
@Column(name = "USERNAME", insertable = false) // insert 시 USERNAME 컬럼에 값이 안들어감.
private String name;
@Column(name = "USERNAME", updatable = false) //update 시 USERNAME 컬럼에 값 수정이 안됨.
private String name;
- nullable : null 허용여부 결정, DDL 생성시 사용
@Column(name = "USERNAME", nullable = false)// 테이블 생성시 USERNAME 컬럼에 not null 제약조건이 들어감
private String name;
- unique : 유니크 제약조건, DDL 생성시 사용
- columnDefinition, length, precision, scale (DDL)
@Temporal
- 날짜 타입 매핑
@Temporal(TemporalType.DATE)
private Date date; //날짜
@Temporal(TemporalType.TIME)
private Date time; //시간
@Temporal(TemporalType.TIMESTAMP)
private Date timeStamp; //날짜와 시간
@Enumerated
- 열거형 매핑
- EnumType.ORDINAL : 순서를 저장(기본값)
- EnumType.STRING : 열거형 이름을 그대로 저장, 가급적 이 것을 사용
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Lob
- CLOB, BLOB 매핑
- CLOB : String, char[], java.sql.CLOB
- BLOB : byte[], java.sql.BLOB
@Lob
private String lobString:
@Lob
private byte[] lobByte;
@Lob 어노테이션은 컨텐츠 길이가 긴 경우 바이너리 파일로 바로 삽입을 해야 하는데 이 때 @Lob 어노테이션이 쓰인다. Lob은 보통 DB에서는 CLOB과 BLOB이 있다. CLOB은 캐릭터를 저장하는 것이고 BLOB은 바이트를 저장한다. @Lob 어노테이션을 String 타입에 쓰면 CLOB이 되고 byte타입에 쓰면 BLOB이 된다.
@Transient
- 이 필드는 매핑하지 않는다.(객체에서만 가지고 있는다.)
- 애플리케이션에서 DB에서 저장하지 않는 필드
하위 컬럼을 DB에서는 매핑을 안하는데 객체에서는 가지고 있고 싶을 때가 있다. 예를 들면 임시플래그 값. 이럴 때 @Transient 어노테이션을 사용하면 DB와 매핑을 하지 않는다. 객체에서만 들고 있다. DB에 넣지도 않고 매핑도 안함. 웬만하면 쓰지 말자.
※ @Column 어노테이션에 속성으로 length를 줄 수 있다. 글자수를 제한한다. 그리고 타입이 String이면 문자 타입으로 매핑하고 int면 숫자타입으로 매핑한다.
@Column(name = "USERNAME", nullable = true, length = 20)
private String name;
JPA에서 엔티티 클래스가 DB와 어떤 식으로 매핑이 되는지 생각하는게 너무 어렵다. 사실 실행을 하면 아래와 같이 테이블이 어떻게 생성됬는지 보이는데 이 걸 보면 어떻게 매핑해야 될 지 쉽게 보인다.

식별자 매핑 어노테이션
- @Id
- @GeneratedValue
@Id @GeneratedValue(strategy = GenerationType.AUTO) // 디폴트가 AUTO이다. 방언을 자동으로 맞춤.
//오라클의 시퀀스처럼 식별자 매핑을 DB에 맡겨버림.
private Long id;
식별자 매핑 방법
- @Id(직접 매핑)
- IDENTITY : 데이터베이스에 위임, MYSQL
- SEQUENCE : 데이터베이스 시퀀스 오브젝트 사용, ORACLE
@SequenceGenerator 필요
- TABLE : 키 생성용 테이블 사용, 모든 DB에서 사용
@TableGenerator 필요
- AUTO : 방언에 따라 자동 지정, 기본값, 위 3가지 방법 중 하나가 자동으로 선택이 되어 사용된다.
실습
아래와 같이 Member 클래스 id 필드를 수정하고, Main 클래스에서 member.setId(); 구문을 주석처리하고 실행해보자.
- @Id @GeneratedValue(strategy = GenerationType.AUTO)
- private Long id;
- try {
- //member 객체를 저장해보자.
- Member member = new Member();
- //member.setId(100L);
아래 실행결과를 보면 하이버네이트가 직접 테이블을 하나 만들어서 시퀀스 값을 얻어온다.

H2 콘솔을 보면 시퀀스 테이블이 생성된 것을 확인할 수 있다. 그래서 따로 식별자 값을 세팅하지 않아도 자동으로 식별자값을 넣을 수 있다.

권장하는 식별자 전략
- 기본 키 제약 조건 : 1. null 아님, 2. 유일, 3. 변하면 안된다.(DB의 식별전략)
- 미래까지 이 조건을 만족하는 자연키는 찾기 어렵다. 대리키(대체키)를 사용하자.
- 대체키라는 건 Oracle 시퀀스나 MySQL auto_increment 등을 말한다. int 타입을 쓰지말자. 10억까지가 한계.
- 예를 들어 주민등록번호도 기본 키로 적절하지 않다.
- 권장 : Long + 대체키 + 키 생성전략 사용(Long 타입이면서 시퀀스를 사용하여)
'IT공부 > JPA' 카테고리의 다른 글
| JPA 6강 - JPA 내부구조 (0) | 2020.05.22 |
|---|---|
| JPA 5강 - 양방향 매핑 (0) | 2020.05.21 |
| JPA 4강 - 연관관계 매핑 (0) | 2020.05.21 |
| JPA 2강 - JPA기초와 매핑 (0) | 2020.05.20 |
| JPA 1강 (0) | 2020.05.19 |



